The first time you watch a coding agent do something useful, it is tempting to conclude that the scarce resource is model intelligence. The agent pauses, thinks, emits a plan, runs a command, reads a failure, edits a file, and after enough of these little loops a pull request appears where previously there was a ticket, which is just close enough to magic that everyone in the room starts asking whether the model should be smarter, cheaper, faster, larger, more agentic, less verbose, better at tool use, or whatever the benchmark discourse is angry about that week.
After enough sessions, especially on repositories that have been around long enough to have opinions, scars, and generated code, the magic starts to look more mechanical. The agent is not mostly sitting there doing pure reasoning. It is waiting for pnpm install, Docker Compose to bring up Postgres, Redis, LocalStack, and the one service nobody wants to admit is still written in Python 3.8.
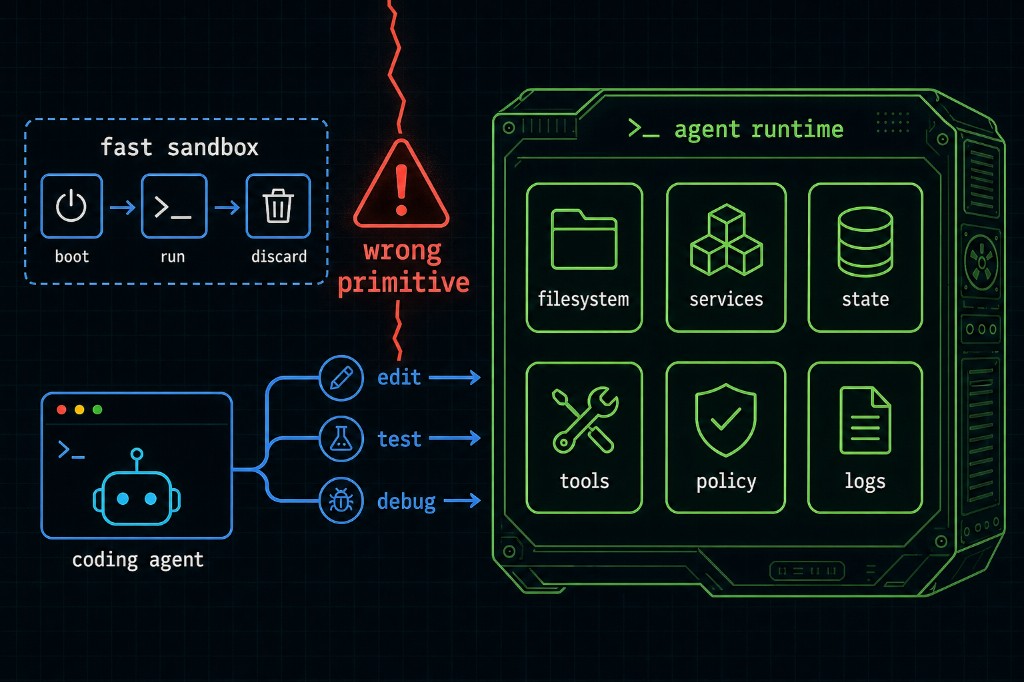
This is the part of agent infrastructure that is easy to miss, because the demos generally stop before the real work begins. A sandbox boots in 300ms. A shell appears. The agent says hello. Great, I like fast things too. But a development environment is not good because it appears quickly; it is good because, three hours later, after the cache is warm but the task has turned ugly, it still has enough CPU, memory, disk, network, filesystem semantics, process isolation, and boring Linux affordances to let the agent run the same verification loop a human engineer would run before sending the diff to another human being.
That is a much less marketable benchmark, which is probably why we do not talk about it enough.
The benchmark came from the wrong workload
Boot time is not a fake metric. It is a perfectly reasonable metric for request-shaped compute. If you are executing untrusted code in response to a user action, running a notebook cell, evaluating a small plugin, giving someone a REPL in the browser, or doing the serverless trick where infrastructure disappears between invocations and then reappears just quickly enough that nobody opens a support ticket, startup latency matters because the user is in the loop and the environment is often disposable.
There is an entire class of sandbox products where this is exactly the right thing to optimize. You want a clean environment, you want it now, you want it cheap, and you want to throw it away before it has time to become anyone’s problem. For that use case, a slow boot is product latency.
Coding agents have a different shape. They are less like a request handler and more like a remote coworker with infinite patience for repetitive edits and a tendency to believe whatever the terminal tells it. In that use case, boot time is not nothing, but it is rarely the center of gravity. If the environment starts in half a second and then spends the next forty minutes acting like a Raspberry Pi under a weighted blanket, the agent will not become more autonomous because the first half second was beautiful. It will just spend more of its life waiting on commands, interpreting timeouts as evidence, substituting fake checks for real checks, and eventually handing a human a diff whose main achievement is that it was produced in an environment nobody should have trusted.
The thing I keep seeing, in conversations with teams trying to move from “one engineer running one agent in a terminal” to “agents can take real tickets and come back with reviewable work”, is that the failure mode is often described as an AI failure even when the root cause is closer to an environment failure. The model missed a regression, but the environment made the real regression test painful to run. The agent changed the wrong layer, but the sandbox could not start the service that would have made the boundary obvious. The PR failed in CI, but CI had a database, daemon, kernel feature, package cache, CPU budget, or network path the agent environment did not have.
Humans survive that kind of mismatch because we have memory and suspicion. We know that npm test is ceremonial but npm run test:integration -- --grep checkout is the thing that actually matters. We know that the first Docker pull on a new machine is a tax, not a signal. We know that the flaky browser test fails only when the CPU is saturated, and that the correct response is not to rewrite the checkout flow at 2 AM.
The agent, unless you have gone to some trouble to teach it otherwise, treats the environment as reality.
The model is not the only computer in the system
Ben Thompson’s “The Inference Shift” makes a distinction that is useful here: answer inference and agentic inference are not the same workload. Answer inference is what happens when a human asks a question and waits for a model to answer, so token latency is a first-order product concern; agentic inference is what happens when a system uses a model as part of a longer task, where state, memory, external tools, and the surrounding execution environment start to matter as much as the raw speed of decoded tokens.
Coding agents are an almost annoyingly literal example of that distinction. The LLM is central, obviously, but the useful work is wrapped around non-LLM operations that look suspiciously like ordinary software engineering. The agent calls tools. The tools run processes. The processes contend for CPU. They allocate memory, touch the filesystem, open sockets, hit package registries, spawn browsers, query databases, and occasionally wedge themselves in ways that require the universal distributed-systems recovery protocol, which is to kill it and try again with more logging.
A typical agent session on a nontrivial repository is full of commands like these:
pnpm install --frozen-lockfile
pnpm turbo run build --filter web
pnpm turbo run test --filter api
tsc --noEmit
docker compose up -d postgres redis localstack
go test ./...
pytest tests/integration -q
npx playwright test checkout.spec.tsThere is no GPU mysticism in that list. There is no model-serving glamour. It is CPU, memory, disk, network, filesystem behavior, service orchestration, and persistence, mediated by the same toolchains we have spent the last decade making faster locally and then somehow forget about the moment an agent is the one typing the command.
The question is not “how fast can an empty environment appear?” The question is “can this environment behave enough like the real one that package installation, typechecking, tests, code search, browser automation, local services, file watching, and long-running debugging sessions all work without the agent quietly switching to a fake workflow?”
What a workstation-shaped runtime needs
The old cloud development environment pitch was, roughly, “your laptop, but in the browser.” That pitch was always a little cursed, because human developers are particular animals; they have editors, shortcuts, local tools, muscle memory, weird dotfiles, and a general unwillingness to debug someone else’s idea of what their workflow should be. But for agents, the remote development environment idea comes back in a different form, because the agent does not need your exact chair height or window manager, and it does not care whether the terminal font has ligatures. It needs the machine-shaped parts of your laptop.
It needs the repository in a real filesystem, not a cute projection that breaks file watching in ways nobody notices until the frontend dev server silently stops rebuilding. It needs enough CPU to keep the edit-test-debug loop from turning into a lunch break. It needs enough memory that parallel test runners, language servers, bundlers, and browsers do not spend the session fighting the OOM killer in an underground parking garage. It needs a way to run the little cluster that modern development has smuggled onto every serious workstation: databases, queues, caches, object stores, mock cloud services, sidecars, worker processes, browser runners, and whatever internal service the codebase assumes is one command away. It needs persistent caches, because downloading the Internet at the start of every task is not a security model, it is a cry for help.
It also needs isolation, obviously, because the reason your laptop works so well is the same reason it is a terrible place to run an autonomous system with shell access. Your laptop has credentials, SSH agents, browser sessions, production config, other repositories, personal files, old secrets, and enough ambient authority to make any security person age visibly. Moving the agent away from the laptop is the right instinct, but if the move strips away the capabilities that made the laptop useful, you have converted a dangerous working environment into a safe broken one.
The interesting architecture is in preserving the useful parts while removing the ambient authority. That tends to lead toward a runtime that looks less like a per-request sandbox and more like a controlled remote workstation: hardware isolation rather than a shared process namespace, policy-mediated access to external services rather than copied credentials, persistent but inspectable state rather than total amnesia, snapshots for risky branches of work, and resource allocations sized around the development loop rather than the marketing screenshot.
That is the primitive I think coding agents are missing: not a faster disposable sandbox, but a controlled remote workstation for non-human developers.
The properties I would rather see
If we were being honest about evaluating agent environments, we would stop asking only how quickly they can produce a prompt and start asking whether they have the properties that let an agent stay inside a real engineering workflow before a human has to rescue the session.
Some of that is measurable in the boring way. Can it start the services the project depends on, and keep them alive across the session? Does file watching behave correctly under the filesystem layer, or does the frontend server miss changes because the runtime is doing something clever? Do dependency caches, language-server indexes, generated artifacts, local databases, and half-finished debugging state persist long enough to become useful? What are the median and p95 runtimes for the repository’s real setup, test, typecheck, browser, and service orchestration commands under agent-like concurrency, with caches cold and warm? How often does CI disagree with the agent environment? How many tasks are abandoned because a required service, kernel feature, browser, package registry, filesystem behavior, or network path was unavailable? What do CPU steal, memory pressure, and I/O wait look like while the agent is doing ordinary development work?
Some of it is harder to compress into a number, but no less real. Does the agent choose the same verification path a senior engineer would choose? Does it run the expensive test when the risk justifies it, or does the environment make that so painful that the agent rationalizes a shortcut? When a command fails, is the failure likely to be about the code, or about the environment? Can a human jump into the session after two hours and understand what happened, or did the runtime erase all the intermediate state in the name of cleanliness?
This is also where cost accounting gets slippery. Underprovisioned compute looks cheap if you stare only at the infrastructure line item, but the system-level bill includes model tokens spent waiting and retrying, CI cycles spent rediscovering failures that should have been caught locally, human review time spent separating real implementation mistakes from environment-induced nonsense, and the organizational tax of engineers deciding, after enough bad PRs, that agents are toys again. A little more CPU can be expensive. Not having it can be worse.
Where this leaves islo.dev
The view we have ended up with at islo.dev is that an agent runtime is not primarily a faster sandbox, although it needs sandboxing, and it is not primarily a cloud development environment, although it needs to preserve much of what made local development useful. It is closer to a secure, policy-controlled, workstation-shaped runtime for non-human developers, which is a ridiculous phrase until you have watched an agent spend an hour trying to work around the fact that its environment cannot run the one command every engineer on the team would have run in minute three.
That pushes the product in less flashy directions than “instant everything.” We care about startup latency, because slow tools are rude, but we care more about whether the environment can run the actual development loop. We care about isolation, but not the kind of isolation that leaves the agent safe and useless. We care about persistence, but not as an excuse to let sandboxes become uninspectable snowflakes. We care about CPU because builds, tests, browsers, code search, language servers, package managers, and local services care about CPU, and an agent that cannot afford to verify its work is just autocomplete with a longer leash.
The trade-off is that this is not as clean as the per-request sandbox story. Long-lived environments are messier than disposable ones. Persistent state creates lifecycle problems. More capable runtimes need stronger policy boundaries. Running a whole local stack inside the agent’s machine complicates isolation, networking, resource accounting, and lifecycle management. Bigger machines cost more. Snapshot and restore semantics get interesting as soon as the agent has a database running, a dev server in the background, three service containers talking to each other, and half a migration applied. None of this fits neatly into a 300ms benchmark, which is annoying, because 300ms benchmarks are fun.
But software engineering has always been full of systems that look worse in the small benchmark and better in the real workload. Coding agents are going to make that lesson painful again. The environment that wins will not be the one that can start the emptiest machine the fastest; it will be the one where, at 2 AM, with CI red, a migration half-written, a browser test failing for a real reason, and an agent trying to decide whether to rerun the expensive check or bluff its way to a PR, the right thing is still cheap enough to do.