There is a workload shape that Kubernetes has never fit particularly cleanly: a long-lived environment, one stable identity, persistent state, mostly idle but occasionally busy, isolated enough to run code you do not fully trust.
This shape has shown up everywhere in agent infrastructure over the last year. A coding agent behaves more like a remote development machine operated by a model than a request handler: it needs a filesystem, tools, package caches, local services, some mediated path to credentials, a network boundary, and enough persistence that the work can continue after the first command fails. Kubernetes is good at stateless services and at numbered replica sets; it does not have a native concept for “this one long-running environment with its own identity and disk.”
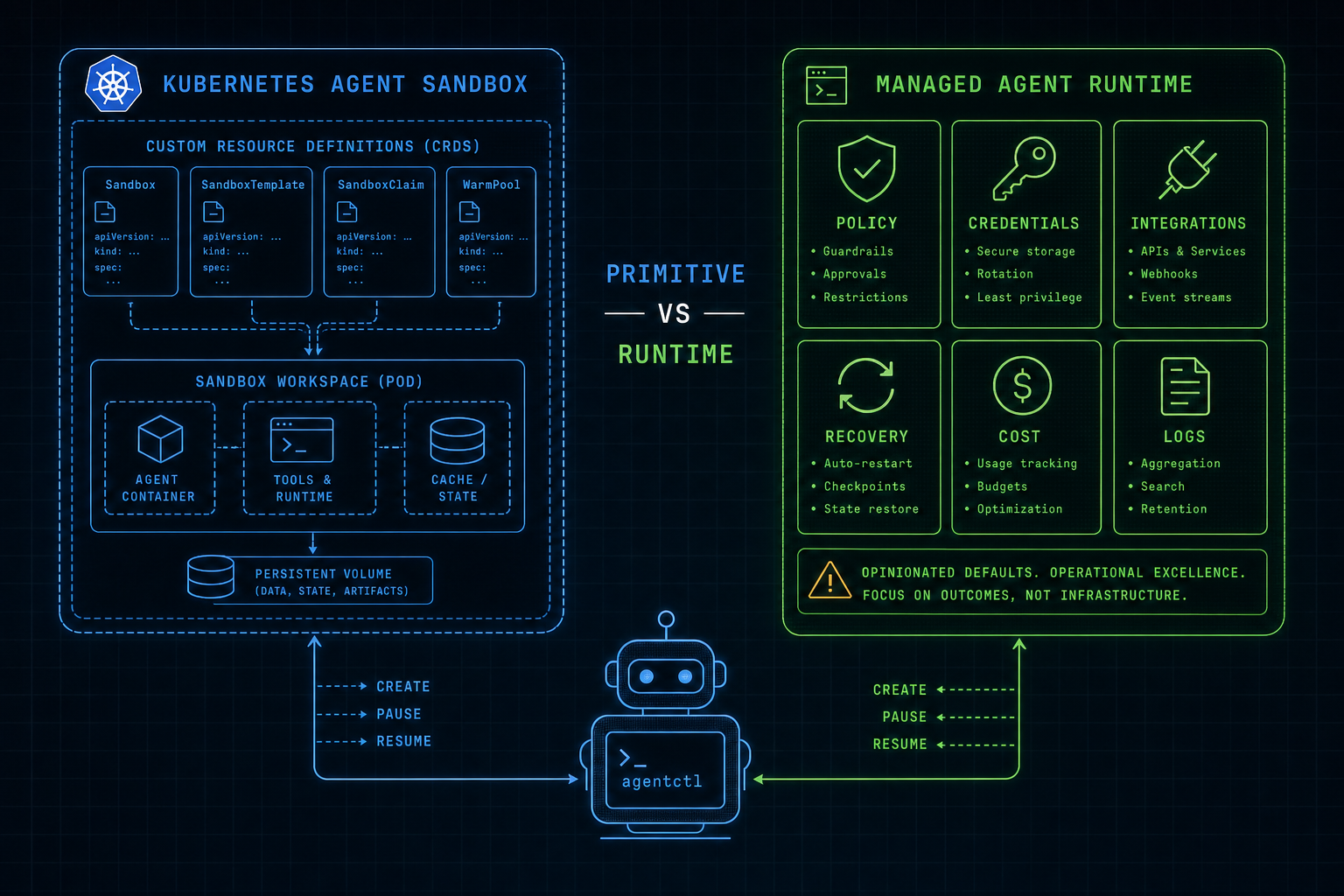
Agent Sandbox is a SIG Apps subproject that fills this gap. It introduces a Sandbox Custom Resource Definition for isolated, stateful, singleton workloads. If you have tried to host agents on Kubernetes, you have probably approximated this with a size-one StatefulSet, a headless Service, and a PersistentVolumeClaim, which works until you need proper hibernation, resume-on-demand, warm pools, or the ability to swap isolation technologies without rewriting your orchestration. Agent Sandbox wraps these concerns into a CRD and controller so each platform team does not have to rebuild them from scratch.
We build Islo, a runtime for coding agents, so this comparison is not impartial. What I can say honestly is that the two projects sit at different layers of the stack, and conflating them leads to bad architectural decisions in both directions.
What Agent Sandbox actually is
Agent Sandbox follows the standard Kubernetes controller pattern. The core resource lives in API group agents.x-k8s.io/v1alpha1:
apiVersion: agents.x-k8s.io/v1alpha1
kind: Sandbox
metadata:
name: my-agent
spec:
podTemplate:
spec:
containers:
- name: agent
image: your-agent-runtime:latestWhen you apply this, the controller creates and manages the underlying Pod. Each Sandbox gets a stable hostname for service discovery, PVC-backed state that survives restarts and hibernation, and lifecycle management: create, pause, resume, scheduled deletion. The API is deliberately close to a Pod spec, which is good design. The new object adds lifecycle semantics without inventing a parallel container model.
The optional extensions add what a platform team needs when sandboxes become a shared service. SandboxTemplate is the reusable blueprint — image, resources, runtime class, storage. SandboxClaim is the request object a user or platform service creates to get a sandbox from a template. SandboxWarmPool keeps pre-warmed sandboxes available so allocation does not always start cold. The flow is ordinary Kubernetes reconciliation: a claim references a template, the controller adopts from the warm pool or creates fresh, and the sandbox reconciles down to a Pod running under the selected runtime class.
One of the better design decisions in the project is separating the API from the isolation technology. The Sandbox CRD does not hardcode a runtime. You select isolation through standard Kubernetes mechanisms — usually runtimeClassName on the pod template — which means you can use gVisor (user-space kernel, good for untrusted code execution), Kata Containers with QEMU, or Kata with Cloud Hypervisor (as in AKS Sandbox), all without touching the Sandbox API. Islo currently uses Cloud Hypervisor for isolation, but Agent Sandbox benefits from the same Kubernetes RuntimeClass ecosystem, so runtime choice alone tells you little about which project to pick. Firecracker differs from QEMU and Cloud Hypervisor at the hypervisor level and sits outside Agent Sandbox’s documented runtime support today.
Agent Sandbox also has real SDK surface area beyond YAML and kubectl. The project ships Python (k8s-agent-sandbox on PyPI) and Go SDKs. The Python SDK includes sandbox.files.read(), sandbox.files.write(), and sandbox.commands.run(), so agent frameworks can interact with sandboxes without shelling out to kubectl exec. All of this is documented and shipped, not roadmap material.
The controller also has operator-facing tuning flags for running at scale:
--sandbox-concurrent-workers=10
--sandbox-claim-concurrent-workers=10
--sandbox-warm-pool-concurrent-workers=10
--sandbox-warm-pool-max-batch-size=500
--kube-api-qps=50
--kube-api-burst=100These exist because Agent Sandbox is infrastructure software, designed for operators who think in QPS and worker counts. The target audience is a platform team, not an individual developer.
Where Agent Sandbox fits
The most defensible argument for Agent Sandbox is “we have a platform team that wants agent environments represented as Kubernetes state.” Almost every serious engineering organization uses Kubernetes somewhere, so that alone is not the bar.
If that is true, a Sandbox is a CRD that other controllers can create, that admission policies can mutate or reject, that GitOps can reconcile, that RBAC can constrain, and that slots into existing observability and autoscaling patterns. If your internal platform is already built around CRDs and controllers, adding agent environments as another reconciled resource fits naturally. The platform team does not have to maintain a separate control plane; they extend the one they already operate.
The second argument is that your organization wants to design its own developer experience. Agent Sandbox gives you Sandbox, SandboxTemplate, SandboxClaim, and SandboxWarmPool, but says nothing about how a developer requests an environment, how approvals work, how snapshots are surfaced, how integrations are configured, or how cost limits are enforced. For some platform teams, this is exactly what they want: a substrate on which to build a custom internal portal, scheduler, or company-specific approval model. For others, those omissions represent a long list of work that still has to get done before the system is usable.
What Agent Sandbox leaves to the platform
This is where the boundary of Agent Sandbox becomes concrete. The CRD creates and manages a stateful isolated workload. It does not decide which external systems an agent can access, how credentials are mediated, which operations require approval, or what audit record is sufficient. Those are not lifecycle concerns; they are runtime concerns that have to be built around the primitive.
Four places make this concrete.
Application-layer policy, not just NetworkPolicy
Kubernetes NetworkPolicy and CNI-level controls handle L3/L4 reachability. They do not inspect individual API requests, inject credentials into outbound calls, classify the intent of an operation, or enforce per-request approval semantics.
Closing that gap requires an application-layer mediation surface: the agent calls a service through a mediated path, and that path handles credential injection, request policy, audit, intent classification, and approval. Agent security covers two distinct problems — preventing breakout from the sandbox, and controlling what legitimate outbound actions mean. A POST to GitHub, a package publish, and a Slack message may all be allowed network destinations, but they have very different risk profiles. Treating them as application-level actions rather than network-level ones gives you a meaningfully different enforcement surface.
Snapshots and rollback, not just persistent disks
Persistent storage and pause/resume behavior are necessary, but they are not a usable recovery model.
Long-running agents install dependencies, edit files, start services, change local databases, and sometimes leave the environment in a bad state. A practical runtime needs snapshot points, rollback semantics, and enough history for a human to understand what changed. Agent Sandbox provides sandbox lifecycle primitives including hibernation, but snapshotting as a developer-facing workflow sits above the CRD.
Scoped integrations with GitHub, Slack, and the rest
A sandbox that can run code still needs safe, scoped connections to GitHub, Slack, Linear, Jira, cloud APIs, package registries, and internal services before it is useful to an agent.
Kubernetes gives you networking and secret distribution mechanisms; it does not give you scoped, revocable, auditable integrations for agent workflows. If an agent needs to create PRs, respond to CI, ask for approval, or notify a team when it is stuck, those behaviors have to be implemented somewhere.
Cost limits at the workflow level, not just the pod
Kubernetes can enforce resource requests, quotas, autoscaling limits, and API throttling. Those controls are necessary but they do not model agent behavior particularly well: runaway reasoning loops, duplicate parallel work, repeated tool failures, expensive external API usage, or cloud resources created during test runs.
A complete runtime needs to surface cost and blast-radius limits at the workflow level, not only at the pod or namespace level.
None of this is a criticism of Agent Sandbox. It is a description of where the boundary is. The project gives Kubernetes a good primitive for the workload; the product semantics go above it.
What sits above the primitive
The layer above Agent Sandbox — whatever it turns out to be — has to solve the problems the CRD deliberately leaves open: credential mediation, application-layer policy, snapshot workflows, integrations with external services, cost controls at the workflow level. These require owning more of the stack than a Kubernetes controller can reasonably standardize across arbitrary cluster configurations.
There are two reasonable shapes for that layer.
Build the layer as Kubernetes controllers
Build controllers, admission policies, and CNI configuration that handle these concerns inside the API server. Everything stays in one control plane. You get composability with existing tooling — HPA, kube-state-metrics, Prometheus Operator conventions all apply automatically. The cost is that your platform team owns the design and implementation of every product-shaped concern: approval flows, integrations, snapshot UX, cost model.
Adopt a managed runtime outside Kubernetes
Own the full vertical outside Kubernetes — compute, isolation, gateway, policy, integrations, billing — and expose it as a hosted service. Adoption is simpler because the runtime ships with the product semantics already decided. The cost is running a separate control plane, which means Kubernetes-native tooling like HPA, kube-state-metrics, and Prometheus Operator conventions no longer apply automatically.
We built Islo as the managed runtime option. It is worth mentioning here mainly to be precise about what the tradeoff actually is: Agent Sandbox’s boundary is not a weakness, it is a design choice. The primitive is composable because it does not make opinions about the layers above it. What you build or adopt above it determines whether that composability is valuable to you or just more work.
How to make the call
Agent Sandbox makes sense when the runtime layer is something your platform team wants to own — not because you use Kubernetes, but because you want agent environments represented as Kubernetes state and you are prepared to build the developer-facing control plane, approval model, integrations, and cost controls around that. If the team is already building an internal platform on top of CRDs and controllers, adding agent environments as another reconciled resource is a natural fit.
If your organization wants to run coding agents without first building the runtime around them, a managed runtime is the more direct path. Agent Sandbox’s roadmap mentions integration with other sandbox offerings, which suggests the ecosystem may converge toward Kubernetes standardizing the lifecycle primitive while runtimes compete on the product semantics above it.
Feedback and corrections welcome: adam@islo.dev.
Further reading: